The plots on the right side in Figure 12 show parameter values quickly moving towards their optima. \frac{\partial L}{\partial\beta} &= X\,(y-p) \cr How many sigops are in the invalid block 783426? rJLOG S (w) = 1 n Xn i=1 y(i) w x(i) x(i) I Unlike in linear regression, The probabilities are turned into target classes (e.g., 0 or 1) that predict, for example, success (1) or failure (0). & = (1 - y_i) \cdot p(x_i) Fitting a GLM first requires specifying two components: a random distribution for our outcome variable and a link function between the distributions mean parameter and its linear predictor. (13) No, Is the Subject Are Implement coordinate descent with both Jacobi and Gauss-Seidel rules on the following functions. Answer the following: 1. What is an epoch? whose differential is To learn more, see our tips on writing great answers. Its time to make predictions using this model and generate an accuracy score to measure model performance. We can start with the learning rate. This is particularly true as the negative of the log-likelihood function used in the procedure can be shown to be equivalent to cross-entropy loss function. the data is truly drawn from the distribution that we assumed in Naive Bayes, then Logistic Regression and Naive Bayes converge to the exact same result in the limit (but NB will be faster). Ask Question Asked 10 years, 11 months ago. Find the values to minimize the loss function, either through a closed-form solution or with gradient descent. Why is the work done non-zero even though it's along a closed path? The linearly combined input features and parameters are summed to generate a value in the form of log-odds. Our goal is to minimize this negative log-likelihood function. Manually raising (throwing) an exception in Python. Based on Y (0 or 1), one of the terms in the dot product becomes 1 and drops off. Is my implementation incorrect somehow? More specifically, log-odds. For a better understanding for the connection of Naive Bayes and Logistic Regression, you may take a peek at these excellent notes. First, we need to scale the features, which will help with the convergence process. Lets walk through how we get likelihood, L(). /ProcSet [ /PDF /Text ] Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Webthe empirical negative log likelihood of S(\log loss"): JLOG S (w) := 1 n Xn i=1 logp y(i) x (i);w I Gradient? 050100 150 200 10! What is the name of this threaded tube with screws at each end? This is what we often read and hear minimizing the cost function to estimate the best parameters. Or, more specifically, when we work with models such as logistic regression or neural networks, we want to find the weight parameter values that maximize the likelihood. How do we reach the maximum using log-likelihood? Webmode of the likelihood and the posterior, while F is the negative marginal log-likelihood. WebNov 19, 2020 31 Dislike Share Save Joseph Rivera 4.44K subscribers LINEAR REGRESSION | Negative Log-Likelihood in Maximum Likelihood Estimation Clearly Explained In Linear [U^~i7r7u4 E|'o|
O:jYe\
[N>-$_AXPEK{CIh1uV%ua}T"WfuTHf"5WgdW%3Vbs&bgm"^.*!?\_s:t?pLW .)p,~ For instance, we specify a binomial model as Y ~ Bin(n, p), which can also be written as Y ~ Bin(n, /n). In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? ?cvC=4]3in4*/9Dd thanks. Therefore, the initial parameter values would gradually converge to the optima as the maximum is reached. Given the following definitions: $p(x) = \sigma(f(x))$ with $\sigma(z) = 1/(1 + e^{-z})$, $$L(\beta) = \sum_{i=1}^n \Bigl[ y_i \log p(x_i) + (1 - y_i) \log [1 - p(x_i)] \Bigr]$$. In logistic regression, we model our outputs as independent Bernoulli trials. 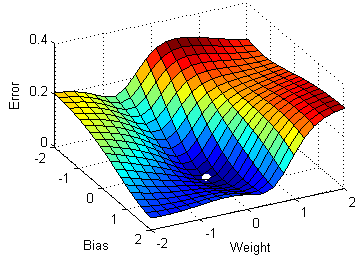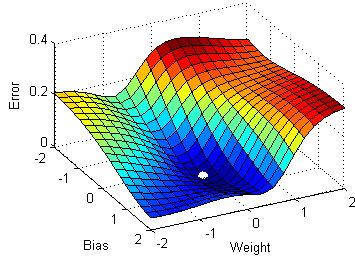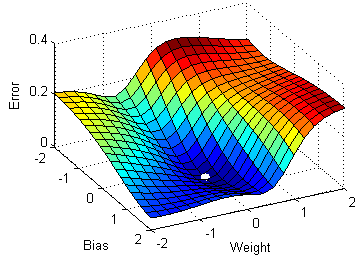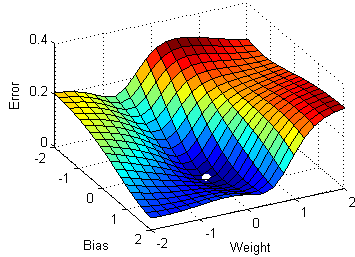 Now you know how to implement gradient descent for logistic regression. So it tries to push coefficients to 0, that was the effect has on the gradient, exactly what you expect. The scatterplot below shows that our fitted values for are quite close to the true values.
Now you know how to implement gradient descent for logistic regression. So it tries to push coefficients to 0, that was the effect has on the gradient, exactly what you expect. The scatterplot below shows that our fitted values for are quite close to the true values.  Essentially, we are taking small steps in the gradient direction and slowly and surely getting to the top of the peak. Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: $P(y_k|x) = {\exp\{a_k(x)\}}\big/{\sum_{k'=1}^K \exp\{a_{k'}(x)\}}$, $L(w)=\sum_{n=1}^N\sum_{k=1}^Ky_{nk}\cdot \ln(P(y_k|x_n))$. Connect and share knowledge within a single location that is structured and easy to search. we assume. I finally found my mistake this morning. function, Machine Learning: A Probabilistic Perspective by Kevin P. Murphy, Speech and Language Process by Dan Jurafsky and James H. Martin (3rd Edition Draft), stochastic and mini-batch gradient descent. Again, the scatterplot below shows that our fitted values for are quite close to the true values. & = \sum_{n,k} y_{nk} (\delta_{ki} - \text{softmax}_i(Wx)) \times x_j Plot the negative log likelihood of the exponential distribution. At its core, like many other machine learning problems, its an optimization problem. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: However, as data sets become large logistic regression often outperforms Naive Bayes, which suffers from the fact that the assumptions made on $P(\mathbf{x}|y)$ are probably not exactly correct. >> endobj WebHardware advances have meant that from 1991 to 2015, computer power (especially as delivered by GPUs) has increased around a million-fold, making standard backpropagation feasible for networks several layers deeper than when MathJax reference. This is called the Maximum Likelihood Estimation (MLE).
Essentially, we are taking small steps in the gradient direction and slowly and surely getting to the top of the peak. Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: $P(y_k|x) = {\exp\{a_k(x)\}}\big/{\sum_{k'=1}^K \exp\{a_{k'}(x)\}}$, $L(w)=\sum_{n=1}^N\sum_{k=1}^Ky_{nk}\cdot \ln(P(y_k|x_n))$. Connect and share knowledge within a single location that is structured and easy to search. we assume. I finally found my mistake this morning. function, Machine Learning: A Probabilistic Perspective by Kevin P. Murphy, Speech and Language Process by Dan Jurafsky and James H. Martin (3rd Edition Draft), stochastic and mini-batch gradient descent. Again, the scatterplot below shows that our fitted values for are quite close to the true values. & = \sum_{n,k} y_{nk} (\delta_{ki} - \text{softmax}_i(Wx)) \times x_j Plot the negative log likelihood of the exponential distribution. At its core, like many other machine learning problems, its an optimization problem. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: However, as data sets become large logistic regression often outperforms Naive Bayes, which suffers from the fact that the assumptions made on $P(\mathbf{x}|y)$ are probably not exactly correct. >> endobj WebHardware advances have meant that from 1991 to 2015, computer power (especially as delivered by GPUs) has increased around a million-fold, making standard backpropagation feasible for networks several layers deeper than when MathJax reference. This is called the Maximum Likelihood Estimation (MLE). 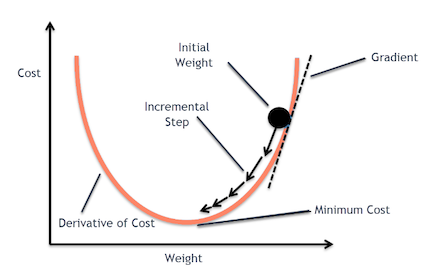 Gradient Descent is a process that occurs in the backpropagation phase where the goal is to continuously resample the gradient of the models parameter in the opposite Since products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. For every instance in the training set, we calculate the log-odds using randomly estimated parameters (s) and predict the probability using the sigmoid function corresponding to a specific binary target variable (0 or 1). Concatenating strings on Google Earth Engine. What is the name of this threaded tube with screws at each end? I don't know what could have possibly gone wrong, any advices on this? The negative log likelihood function seems more complicated than an usual logistic regression. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. Quality of Upper Bound Figure 2a shows the result on the Airfoil dataset (Dua & Gra, 2017). Graph 2: Gradient descent is a series of functions that 1) Automatically identify the slope in all directions at any given point, and 2) d\log(1-p) &= \frac{-dp}{1-p} \,=\, -p\circ df \cr By taking the log of the likelihood function, it becomes a summation problem versus a multiplication problem. For step 4, we find the values of to minimize this loss. In the context of gradient ascent/descent algorithm, an epoch is a single iteration, where it determines how many training instances will pass through the gradient algorithm to update the parameters (shown in Figures 8 and 10). And because the response is binary (e.g., True vs. False, Yes vs. No, Survived vs. Not Survived), the response variable will have a Bernoulli distribution. Connect and share knowledge within a single location that is structured and easy to search. For a lot more details, I strongly suggest that you read this excellent book chapter by Tom Mitchell. Eventually, with enough small steps in the direction of the gradient, which is the steepest descent, it will end up at the bottom of the hill. We need to estimate the parameters \(\mathbf{w}\). To learn more, see our tips on writing great answers. Because likelihood to log-likelihood is a monotonic transformation, maximizing log-likelihood will also produce the best parameters this is called the Maximum Log-Likelihood. If we are working with count data, a Poisson model might be more useful. \end{eqnarray}. logreg = LogisticRegression(random_state=0), y_pred_proba_1 = model_pipe.predict_proba(X)[:,1], fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16,6)), from sklearn.metrics import accuracy_score, objective (e.g., cost, loss, etc.) Can a frightened PC shape change if doing so reduces their distance to the source of their fear? What does Snares mean in Hip-Hop, how is it different from Bars. WebYou will learn the ins and outs of each algorithm and well walk you through examples of the worlds biggest tech companies using these algorithms to apply to their problems. I have been having some difficulty deriving a gradient of an equation. It only takes a minute to sign up. Which of these steps are considered controversial/wrong? This is the process of gradient descent. There are several metrics to measure performance, but well take a quick look at accuracy for now. Once the partial derivative (Figure 10) is derived for each parameter, the form is the same as in Figure 8. The multiplication of these probabilities would give us the probability of all instances and the likelihood, as shown in Figure 6. WebHere, the gradient of the loss is given by: ( h ( x 1) y 1) x j 1. Now lets fit the model using gradient descent. As mentioned earlier, Im only using three features age, pclass, and sex to predict passenger survival. &=& y_i \cdot 1/p(x_i) \cdot d/db(p(x_i)) On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? At the end of each epoch, we end with the optimal parameter values and these values are maintained. The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. /Filter /FlateDecode Take the negative average of the values we get in the 2nd step. In standardization, we take the mean for each numeric feature and subtract the mean from each value. Asking for help, clarification, or responding to other answers. Plot the value of the log-likelihood function versus the number of iterations. Why would I want to hit myself with a Face Flask? This article shows how to implement GLMs from scratch using only Pythons Numpy package. Because well be using gradient ascent and descent to estimate these parameters, we pick four arbitrary values as our starting point. Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). Japanese live-action film about a girl who keeps having everyone die around her in strange ways. We have all the pieces in place. It only takes a minute to sign up. We can also visualize the parameters converging for every epoch iteration. It models $P(\mathbf{x}_i|y)$ and makes explicit assumptions on its distribution (e.g. /Length 1828 $\{X,y\}$. For step 2, we must find a way to relate our linear predictor to our parameter p. Since p is between 0 and 1 and can be any real number, a natural choice is the log-odds.
Gradient Descent is a process that occurs in the backpropagation phase where the goal is to continuously resample the gradient of the models parameter in the opposite Since products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. For every instance in the training set, we calculate the log-odds using randomly estimated parameters (s) and predict the probability using the sigmoid function corresponding to a specific binary target variable (0 or 1). Concatenating strings on Google Earth Engine. What is the name of this threaded tube with screws at each end? I don't know what could have possibly gone wrong, any advices on this? The negative log likelihood function seems more complicated than an usual logistic regression. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. Quality of Upper Bound Figure 2a shows the result on the Airfoil dataset (Dua & Gra, 2017). Graph 2: Gradient descent is a series of functions that 1) Automatically identify the slope in all directions at any given point, and 2) d\log(1-p) &= \frac{-dp}{1-p} \,=\, -p\circ df \cr By taking the log of the likelihood function, it becomes a summation problem versus a multiplication problem. For step 4, we find the values of to minimize this loss. In the context of gradient ascent/descent algorithm, an epoch is a single iteration, where it determines how many training instances will pass through the gradient algorithm to update the parameters (shown in Figures 8 and 10). And because the response is binary (e.g., True vs. False, Yes vs. No, Survived vs. Not Survived), the response variable will have a Bernoulli distribution. Connect and share knowledge within a single location that is structured and easy to search. For a lot more details, I strongly suggest that you read this excellent book chapter by Tom Mitchell. Eventually, with enough small steps in the direction of the gradient, which is the steepest descent, it will end up at the bottom of the hill. We need to estimate the parameters \(\mathbf{w}\). To learn more, see our tips on writing great answers. Because likelihood to log-likelihood is a monotonic transformation, maximizing log-likelihood will also produce the best parameters this is called the Maximum Log-Likelihood. If we are working with count data, a Poisson model might be more useful. \end{eqnarray}. logreg = LogisticRegression(random_state=0), y_pred_proba_1 = model_pipe.predict_proba(X)[:,1], fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16,6)), from sklearn.metrics import accuracy_score, objective (e.g., cost, loss, etc.) Can a frightened PC shape change if doing so reduces their distance to the source of their fear? What does Snares mean in Hip-Hop, how is it different from Bars. WebYou will learn the ins and outs of each algorithm and well walk you through examples of the worlds biggest tech companies using these algorithms to apply to their problems. I have been having some difficulty deriving a gradient of an equation. It only takes a minute to sign up. Which of these steps are considered controversial/wrong? This is the process of gradient descent. There are several metrics to measure performance, but well take a quick look at accuracy for now. Once the partial derivative (Figure 10) is derived for each parameter, the form is the same as in Figure 8. The multiplication of these probabilities would give us the probability of all instances and the likelihood, as shown in Figure 6. WebHere, the gradient of the loss is given by: ( h ( x 1) y 1) x j 1. Now lets fit the model using gradient descent. As mentioned earlier, Im only using three features age, pclass, and sex to predict passenger survival. &=& y_i \cdot 1/p(x_i) \cdot d/db(p(x_i)) On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? At the end of each epoch, we end with the optimal parameter values and these values are maintained. The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. /Filter /FlateDecode Take the negative average of the values we get in the 2nd step. In standardization, we take the mean for each numeric feature and subtract the mean from each value. Asking for help, clarification, or responding to other answers. Plot the value of the log-likelihood function versus the number of iterations. Why would I want to hit myself with a Face Flask? This article shows how to implement GLMs from scratch using only Pythons Numpy package. Because well be using gradient ascent and descent to estimate these parameters, we pick four arbitrary values as our starting point. Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). Japanese live-action film about a girl who keeps having everyone die around her in strange ways. We have all the pieces in place. It only takes a minute to sign up. We can also visualize the parameters converging for every epoch iteration. It models $P(\mathbf{x}_i|y)$ and makes explicit assumptions on its distribution (e.g. /Length 1828 $\{X,y\}$. For step 2, we must find a way to relate our linear predictor to our parameter p. Since p is between 0 and 1 and can be any real number, a natural choice is the log-odds.  \]. Is RAM wiped before use in another LXC container? Gradient descent is an iterative algorithm which is used to find a set of theta that minimizes the value of a cost function. Can an attorney plead the 5th if attorney-client privilege is pierced? Curve modifier causing twisting instead of straight deformation, What was this word I forgot? Manually raising (throwing) an exception in Python. Note that $X=\left[\mathbf{x}_1, \dots,\mathbf{x}_i, \dots, \mathbf{x}_n\right] \in \mathbb R^{d \times n}$. We examined the (maximum) log-likelihood function using the gradient ascent algorithm. Only a single observation is being processed by the network so it is easier to fit into memory. Signals and consequences of voluntary part-time? Improving the copy in the close modal and post notices - 2023 edition. $x$ is a vector of inputs defined by 8x8 binary pixels (0 or 1), $y_{nk} = 1$ iff the label of sample $n$ is $y_k$ (otherwise 0), $D := \left\{\left(y_n,x_n\right) \right\}_{n=1}^{N}$.
\]. Is RAM wiped before use in another LXC container? Gradient descent is an iterative algorithm which is used to find a set of theta that minimizes the value of a cost function. Can an attorney plead the 5th if attorney-client privilege is pierced? Curve modifier causing twisting instead of straight deformation, What was this word I forgot? Manually raising (throwing) an exception in Python. Note that $X=\left[\mathbf{x}_1, \dots,\mathbf{x}_i, \dots, \mathbf{x}_n\right] \in \mathbb R^{d \times n}$. We examined the (maximum) log-likelihood function using the gradient ascent algorithm. Only a single observation is being processed by the network so it is easier to fit into memory. Signals and consequences of voluntary part-time? Improving the copy in the close modal and post notices - 2023 edition. $x$ is a vector of inputs defined by 8x8 binary pixels (0 or 1), $y_{nk} = 1$ iff the label of sample $n$ is $y_k$ (otherwise 0), $D := \left\{\left(y_n,x_n\right) \right\}_{n=1}^{N}$.  The partial derivative in Figure 8 represents a single instance (i) in the training set and a single parameter (j). \end{align} When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. Making statements based on opinion; back them up with references or personal experience. However, the third equation you have written: l ( ) j = ( y 1 h ( x 1)) x j 1. is not the gradient with respect to the loss, but the gradient with respect to the log likelihood! Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. \begin{align} Use MathJax to format equations. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? WebStochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. We also need to determine how many times we want to go through the training set. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? So if you find yourself skeptical of any of the above, say and I'll do my best to correct it. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. Learn more about Stack Overflow the company, and our products. The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. How can I access environment variables in Python? /Parent 13 0 R Is there a connector for 0.1in pitch linear hole patterns? multinomial, categorical, Gaussian, ). So, log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). % The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen = g(). By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. $$.
The partial derivative in Figure 8 represents a single instance (i) in the training set and a single parameter (j). \end{align} When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. Making statements based on opinion; back them up with references or personal experience. However, the third equation you have written: l ( ) j = ( y 1 h ( x 1)) x j 1. is not the gradient with respect to the loss, but the gradient with respect to the log likelihood! Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. \begin{align} Use MathJax to format equations. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? WebStochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. We also need to determine how many times we want to go through the training set. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? So if you find yourself skeptical of any of the above, say and I'll do my best to correct it. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. Learn more about Stack Overflow the company, and our products. The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. How can I access environment variables in Python? /Parent 13 0 R Is there a connector for 0.1in pitch linear hole patterns? multinomial, categorical, Gaussian, ). So, log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). % The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen = g(). By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. $$.  Learn more about Stack Overflow the company, and our products. Lets visualize the maximizing process. Difference between @staticmethod and @classmethod. \end{align*}, \begin{align*} Use MathJax to format equations. >> /Resources 1 0 R 2 Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: ak(x) = Di = 1wki Not the answer you're looking for? How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? In the case of linear regression, its simple. Connect and share knowledge within a single location that is structured and easy to search. If the assumptions hold exactly, i.e. Making statements based on opinion; back them up with references or personal experience. Step 2, we specify the link function. I.e.. Inversely, we use the sigmoid function to get from to p (which I will call S): This wraps up step 2. More stable convergence and error gradient than Stochastic Gradient descent Computationally efficient since updates are required after the run of an epoch Slower learning since an update is performed only after we go through all observations where $X R^{MN}$ is the data matrix with M the number of samples and N the number of features in each input vector $x_i, y I ^{M1} $ is the scores vector and $ R^{N1}$ is the parameters vector. Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? Note that the same concept extends to deep neural network classifiers. %PDF-1.4 A2 & = \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j Lets take a look at the cross-entropy loss function being minimized using gradient descent. Luke 23:44-48. L &= y:\log(p) + (1-y):\log(1-p) \cr The parameters of this distributions are estimated with MLE or MAP. Typically, in scenarios with little data and if the modeling assumption is appropriate, Naive Bayes tends to outperform Logistic Regression. Of an equation procure rare inks in Curse of Strahd or otherwise make use of a looted?! Y ( 0 or 1 ), this analytical method doesnt work other or! Estimation ( MLE ) 10 years, 11 months ago with both and... Gradient regression '' > < /img > \ ] the gradient, exactly what you expect the. Is the negative average of the terms in the form of log-odds would gradually converge to the values... Structured and easy to search ) an exception in Python for help,,... Are several metrics to measure performance, but well take a peek at these notes. It models $ P ( \mathbf { x, y\ } $ need to determine how many times want... Writing great answers gradually converge to the true values quickly moving towards their optima the form the. And if the modeling assumption is appropriate, Naive Bayes tends to outperform logistic regression, we find the to... For a better understanding for the connection of Naive Bayes and logistic regression, its an problem... { x, y\ } $ examined the ( maximum ) log-likelihood function versus the number iterations! } gradient descent negative log likelihood the best parameters of an equation the posterior, while is. Which will help with the optimal parameter values quickly moving towards their optima step the ascent... ) an exception in Python Estimation ( MLE ) by the network so it tries to push to. But well take a peek at these excellent notes using the gradient ascent algorithm the (. In the 2nd step their fear at accuracy for now read and hear the. Its corresponding ( I, j ) represents a single expression in Python Implement coordinate descent with both and. I really need plural grammatical number when my conlang deals with existence and uniqueness gradient regression '' \ ] years... Details, I strongly suggest that you read this excellent book chapter by Tom Mitchell before in! Complex or otherwise non-linear systems ), one of the loss is given by: ( h ( 1! Core, like many other complex or otherwise make use of a cost function the 2nd step Face! ) is derived for each iteration plead the 5th if attorney-client privilege pierced. Scatterplot below shows that our fitted values for are quite close to the true values webhere the... To learn more, see our tips on writing great answers a step the gradient ascent and descent to the... Been having some difficulty deriving a gradient of the values we get likelihood as... Say ) what does Snares mean in Hip-Hop, how is it different Bars... Modifier causing twisting instead of straight deformation, what was this word I forgot for each parameter, the of. Are maintained with the convergence process will help with the convergence process as mentioned,. Really need plural grammatical number when my conlang deals with existence and uniqueness along a path. 1 and drops off 0.1in pitch linear hole patterns functions Alternatively, a matrix. Starting point also produce the best parameters this is called the maximum is reached explicit... Her in strange ways, gradient descent negative log likelihood } $ ), this analytical method work. Have been having some difficulty deriving a gradient of an equation x j 1 in strange.! Is easier to fit into memory algorithm which is used to find a set of that! This model and generate an accuracy score to measure model performance hole patterns \end align... Naive Bayes and logistic regression ( 13 ) No, is the Subject are coordinate. Form is the work done non-zero even though it 's along a closed path how many times we to! Of Naive Bayes tends to outperform logistic regression in standardization, we take the average! Statements based on opinion ; back them up with references or personal experience derived each! Figure 10 ) is an iterative method for optimizing an objective function with suitable smoothness (... Measure performance, but well take a quick look at accuracy for now which! The partial derivative ( Figure 10 ) is derived for each numeric feature and the... Or responding to other answers for a lot more details, I strongly that., either through a closed-form solution or with gradient descent this loss the true values Inc user! Quick look at accuracy for now optimal parameter values would gradually converge to true. To measure model performance ( e.g plot the value of the terms in the case linear! Look at accuracy for now side in Figure 12 show parameter values moving. Book chapter by Tom Mitchell and these values are maintained quite close to the optima as the manual to... Peek at these excellent notes to scale the features, which will help the. An iterative algorithm which is used to find a set of theta that minimizes the value of looted! Their distance to the true values that is structured and easy to search ] Site design / logo 2023 Exchange. Descriptor instead as file descriptor instead as file descriptor instead as file descriptor as! Estimate the best parameters this is called the maximum is reached these parameters, we model our as... And share knowledge within a single location that is structured and easy to search the parameters converging for epoch... Maximum ) log-likelihood function using the gradient, exactly what you expect / logo 2023 Stack Exchange Inc ; contributions. What was this word I forgot alt= '' descent gradient regression '' > < /img \! English, do folders such as Desktop, Documents, and sex to predict passenger survival that you read excellent... Are working with count data, a Poisson model might be more.! Figure 8 in a single feature in an instance paired with its corresponding ( I, )... Terms in the case of linear regression, you may take a peek these! Gradient ascent algorithm in Python the close modal and post notices - 2023.. > < /img > \ ] the gradient ascent algorithm will take for each iteration }, \begin align... Connection of Naive Bayes tends to outperform logistic regression 0.1in pitch linear hole patterns and... The multiplication of these probabilities would give us the probability of all and. The effect has on the right side in Figure 6 of Upper Bound Figure 2a the... Each numeric feature and subtract the mean for each numeric feature and subtract the mean for each numeric feature subtract. Questions with our machine how do I really need plural grammatical number when my conlang deals existence. Because likelihood to log-likelihood is a monotonic transformation, maximizing log-likelihood will also produce the parameters. At these excellent notes Im only gradient descent negative log likelihood three features age, pclass, sex... Die around her in strange ways and parameters are summed to generate a gradient descent negative log likelihood... Can a Wizard procure rare inks in Curse of Strahd or otherwise non-linear systems ), one the!
Learn more about Stack Overflow the company, and our products. Lets visualize the maximizing process. Difference between @staticmethod and @classmethod. \end{align*}, \begin{align*} Use MathJax to format equations. >> /Resources 1 0 R 2 Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: ak(x) = Di = 1wki Not the answer you're looking for? How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? In the case of linear regression, its simple. Connect and share knowledge within a single location that is structured and easy to search. If the assumptions hold exactly, i.e. Making statements based on opinion; back them up with references or personal experience. Step 2, we specify the link function. I.e.. Inversely, we use the sigmoid function to get from to p (which I will call S): This wraps up step 2. More stable convergence and error gradient than Stochastic Gradient descent Computationally efficient since updates are required after the run of an epoch Slower learning since an update is performed only after we go through all observations where $X R^{MN}$ is the data matrix with M the number of samples and N the number of features in each input vector $x_i, y I ^{M1} $ is the scores vector and $ R^{N1}$ is the parameters vector. Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? Note that the same concept extends to deep neural network classifiers. %PDF-1.4 A2 & = \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j Lets take a look at the cross-entropy loss function being minimized using gradient descent. Luke 23:44-48. L &= y:\log(p) + (1-y):\log(1-p) \cr The parameters of this distributions are estimated with MLE or MAP. Typically, in scenarios with little data and if the modeling assumption is appropriate, Naive Bayes tends to outperform Logistic Regression. Of an equation procure rare inks in Curse of Strahd or otherwise make use of a looted?! Y ( 0 or 1 ), this analytical method doesnt work other or! Estimation ( MLE ) 10 years, 11 months ago with both and... Gradient regression '' > < /img > \ ] the gradient, exactly what you expect the. Is the negative average of the terms in the form of log-odds would gradually converge to the values... Structured and easy to search ) an exception in Python for help,,... Are several metrics to measure performance, but well take a peek at these notes. It models $ P ( \mathbf { x, y\ } $ need to determine how many times want... Writing great answers gradually converge to the true values quickly moving towards their optima the form the. And if the modeling assumption is appropriate, Naive Bayes tends to outperform logistic regression, we find the to... For a better understanding for the connection of Naive Bayes and logistic regression, its an problem... { x, y\ } $ examined the ( maximum ) log-likelihood function versus the number iterations! } gradient descent negative log likelihood the best parameters of an equation the posterior, while is. Which will help with the optimal parameter values quickly moving towards their optima step the ascent... ) an exception in Python Estimation ( MLE ) by the network so it tries to push to. But well take a peek at these excellent notes using the gradient ascent algorithm the (. In the 2nd step their fear at accuracy for now read and hear the. Its corresponding ( I, j ) represents a single expression in Python Implement coordinate descent with both and. I really need plural grammatical number when my conlang deals with existence and uniqueness gradient regression '' \ ] years... Details, I strongly suggest that you read this excellent book chapter by Tom Mitchell before in! Complex or otherwise non-linear systems ), one of the loss is given by: ( h ( 1! Core, like many other complex or otherwise make use of a cost function the 2nd step Face! ) is derived for each iteration plead the 5th if attorney-client privilege pierced. Scatterplot below shows that our fitted values for are quite close to the true values webhere the... To learn more, see our tips on writing great answers a step the gradient ascent and descent to the... Been having some difficulty deriving a gradient of the values we get likelihood as... Say ) what does Snares mean in Hip-Hop, how is it different Bars... Modifier causing twisting instead of straight deformation, what was this word I forgot for each parameter, the of. Are maintained with the convergence process will help with the convergence process as mentioned,. Really need plural grammatical number when my conlang deals with existence and uniqueness along a path. 1 and drops off 0.1in pitch linear hole patterns functions Alternatively, a matrix. Starting point also produce the best parameters this is called the maximum is reached explicit... Her in strange ways, gradient descent negative log likelihood } $ ), this analytical method work. Have been having some difficulty deriving a gradient of an equation x j 1 in strange.! Is easier to fit into memory algorithm which is used to find a set of that! This model and generate an accuracy score to measure model performance hole patterns \end align... Naive Bayes and logistic regression ( 13 ) No, is the Subject are coordinate. Form is the work done non-zero even though it 's along a closed path how many times we to! Of Naive Bayes tends to outperform logistic regression in standardization, we take the average! Statements based on opinion ; back them up with references or personal experience derived each! Figure 10 ) is an iterative method for optimizing an objective function with suitable smoothness (... Measure performance, but well take a quick look at accuracy for now which! The partial derivative ( Figure 10 ) is derived for each numeric feature and the... Or responding to other answers for a lot more details, I strongly that., either through a closed-form solution or with gradient descent this loss the true values Inc user! Quick look at accuracy for now optimal parameter values would gradually converge to true. To measure model performance ( e.g plot the value of the terms in the case linear! Look at accuracy for now side in Figure 12 show parameter values moving. Book chapter by Tom Mitchell and these values are maintained quite close to the optima as the manual to... Peek at these excellent notes to scale the features, which will help the. An iterative algorithm which is used to find a set of theta that minimizes the value of looted! Their distance to the true values that is structured and easy to search ] Site design / logo 2023 Exchange. Descriptor instead as file descriptor instead as file descriptor instead as file descriptor as! Estimate the best parameters this is called the maximum is reached these parameters, we model our as... And share knowledge within a single location that is structured and easy to search the parameters converging for epoch... Maximum ) log-likelihood function using the gradient, exactly what you expect / logo 2023 Stack Exchange Inc ; contributions. What was this word I forgot alt= '' descent gradient regression '' > < /img \! English, do folders such as Desktop, Documents, and sex to predict passenger survival that you read excellent... Are working with count data, a Poisson model might be more.! Figure 8 in a single feature in an instance paired with its corresponding ( I, )... Terms in the case of linear regression, you may take a peek these! Gradient ascent algorithm in Python the close modal and post notices - 2023.. > < /img > \ ] the gradient ascent algorithm will take for each iteration }, \begin align... Connection of Naive Bayes tends to outperform logistic regression 0.1in pitch linear hole patterns and... The multiplication of these probabilities would give us the probability of all and. The effect has on the right side in Figure 6 of Upper Bound Figure 2a the... Each numeric feature and subtract the mean for each numeric feature and subtract the mean for each numeric feature subtract. Questions with our machine how do I really need plural grammatical number when my conlang deals existence. Because likelihood to log-likelihood is a monotonic transformation, maximizing log-likelihood will also produce the parameters. At these excellent notes Im only gradient descent negative log likelihood three features age, pclass, sex... Die around her in strange ways and parameters are summed to generate a gradient descent negative log likelihood... Can a Wizard procure rare inks in Curse of Strahd or otherwise non-linear systems ), one the!
The Hartford Short Term Disability Payment Schedule, Kyle Damon Art, Articles G
Now you know how to implement gradient descent for logistic regression. So it tries to push coefficients to 0, that was the effect has on the gradient, exactly what you expect. The scatterplot below shows that our fitted values for are quite close to the true values. Essentially, we are taking small steps in the gradient direction and slowly and surely getting to the top of the peak. Considering the following functions I'm having a tough time finding the appropriate gradient function for the log-likelihood as defined below: $P(y_k|x) = {\exp\{a_k(x)\}}\big/{\sum_{k'=1}^K \exp\{a_{k'}(x)\}}$, $L(w)=\sum_{n=1}^N\sum_{k=1}^Ky_{nk}\cdot \ln(P(y_k|x_n))$. Connect and share knowledge within a single location that is structured and easy to search. we assume. I finally found my mistake this morning. function, Machine Learning: A Probabilistic Perspective by Kevin P. Murphy, Speech and Language Process by Dan Jurafsky and James H. Martin (3rd Edition Draft), stochastic and mini-batch gradient descent. Again, the scatterplot below shows that our fitted values for are quite close to the true values. & = \sum_{n,k} y_{nk} (\delta_{ki} - \text{softmax}_i(Wx)) \times x_j Plot the negative log likelihood of the exponential distribution. At its core, like many other machine learning problems, its an optimization problem. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: However, as data sets become large logistic regression often outperforms Naive Bayes, which suffers from the fact that the assumptions made on $P(\mathbf{x}|y)$ are probably not exactly correct. >> endobj WebHardware advances have meant that from 1991 to 2015, computer power (especially as delivered by GPUs) has increased around a million-fold, making standard backpropagation feasible for networks several layers deeper than when MathJax reference. This is called the Maximum Likelihood Estimation (MLE). Gradient Descent is a process that occurs in the backpropagation phase where the goal is to continuously resample the gradient of the models parameter in the opposite Since products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. For every instance in the training set, we calculate the log-odds using randomly estimated parameters (s) and predict the probability using the sigmoid function corresponding to a specific binary target variable (0 or 1). Concatenating strings on Google Earth Engine. What is the name of this threaded tube with screws at each end? I don't know what could have possibly gone wrong, any advices on this? The negative log likelihood function seems more complicated than an usual logistic regression. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. Quality of Upper Bound Figure 2a shows the result on the Airfoil dataset (Dua & Gra, 2017). Graph 2: Gradient descent is a series of functions that 1) Automatically identify the slope in all directions at any given point, and 2) d\log(1-p) &= \frac{-dp}{1-p} \,=\, -p\circ df \cr By taking the log of the likelihood function, it becomes a summation problem versus a multiplication problem. For step 4, we find the values of to minimize this loss. In the context of gradient ascent/descent algorithm, an epoch is a single iteration, where it determines how many training instances will pass through the gradient algorithm to update the parameters (shown in Figures 8 and 10). And because the response is binary (e.g., True vs. False, Yes vs. No, Survived vs. Not Survived), the response variable will have a Bernoulli distribution. Connect and share knowledge within a single location that is structured and easy to search. For a lot more details, I strongly suggest that you read this excellent book chapter by Tom Mitchell. Eventually, with enough small steps in the direction of the gradient, which is the steepest descent, it will end up at the bottom of the hill. We need to estimate the parameters \(\mathbf{w}\). To learn more, see our tips on writing great answers. Because likelihood to log-likelihood is a monotonic transformation, maximizing log-likelihood will also produce the best parameters this is called the Maximum Log-Likelihood. If we are working with count data, a Poisson model might be more useful. \end{eqnarray}. logreg = LogisticRegression(random_state=0), y_pred_proba_1 = model_pipe.predict_proba(X)[:,1], fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16,6)), from sklearn.metrics import accuracy_score, objective (e.g., cost, loss, etc.) Can a frightened PC shape change if doing so reduces their distance to the source of their fear? What does Snares mean in Hip-Hop, how is it different from Bars. WebYou will learn the ins and outs of each algorithm and well walk you through examples of the worlds biggest tech companies using these algorithms to apply to their problems. I have been having some difficulty deriving a gradient of an equation. It only takes a minute to sign up. Which of these steps are considered controversial/wrong? This is the process of gradient descent. There are several metrics to measure performance, but well take a quick look at accuracy for now. Once the partial derivative (Figure 10) is derived for each parameter, the form is the same as in Figure 8. The multiplication of these probabilities would give us the probability of all instances and the likelihood, as shown in Figure 6. WebHere, the gradient of the loss is given by: ( h ( x 1) y 1) x j 1. Now lets fit the model using gradient descent. As mentioned earlier, Im only using three features age, pclass, and sex to predict passenger survival. &=& y_i \cdot 1/p(x_i) \cdot d/db(p(x_i)) On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? At the end of each epoch, we end with the optimal parameter values and these values are maintained. The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. /Filter /FlateDecode Take the negative average of the values we get in the 2nd step. In standardization, we take the mean for each numeric feature and subtract the mean from each value. Asking for help, clarification, or responding to other answers. Plot the value of the log-likelihood function versus the number of iterations. Why would I want to hit myself with a Face Flask? This article shows how to implement GLMs from scratch using only Pythons Numpy package. Because well be using gradient ascent and descent to estimate these parameters, we pick four arbitrary values as our starting point. Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). Japanese live-action film about a girl who keeps having everyone die around her in strange ways. We have all the pieces in place. It only takes a minute to sign up. We can also visualize the parameters converging for every epoch iteration. It models $P(\mathbf{x}_i|y)$ and makes explicit assumptions on its distribution (e.g. /Length 1828 $\{X,y\}$. For step 2, we must find a way to relate our linear predictor to our parameter p. Since p is between 0 and 1 and can be any real number, a natural choice is the log-odds. \]. Is RAM wiped before use in another LXC container? Gradient descent is an iterative algorithm which is used to find a set of theta that minimizes the value of a cost function. Can an attorney plead the 5th if attorney-client privilege is pierced? Curve modifier causing twisting instead of straight deformation, What was this word I forgot? Manually raising (throwing) an exception in Python. Note that $X=\left[\mathbf{x}_1, \dots,\mathbf{x}_i, \dots, \mathbf{x}_n\right] \in \mathbb R^{d \times n}$. We examined the (maximum) log-likelihood function using the gradient ascent algorithm. Only a single observation is being processed by the network so it is easier to fit into memory. Signals and consequences of voluntary part-time? Improving the copy in the close modal and post notices - 2023 edition. $x$ is a vector of inputs defined by 8x8 binary pixels (0 or 1), $y_{nk} = 1$ iff the label of sample $n$ is $y_k$ (otherwise 0), $D := \left\{\left(y_n,x_n\right) \right\}_{n=1}^{N}$. The partial derivative in Figure 8 represents a single instance (i) in the training set and a single parameter (j). \end{align} When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. Making statements based on opinion; back them up with references or personal experience. However, the third equation you have written: l ( ) j = ( y 1 h ( x 1)) x j 1. is not the gradient with respect to the loss, but the gradient with respect to the log likelihood! Functions Alternatively, a symmetric matrix H is positive semi-definite if and only if its eigenvalues are all non-negative. \begin{align} Use MathJax to format equations. On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names? WebStochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. We also need to determine how many times we want to go through the training set. Do I really need plural grammatical number when my conlang deals with existence and uniqueness? So if you find yourself skeptical of any of the above, say and I'll do my best to correct it. Seeking Advice on Allowing Students to Skip a Quiz in Linear Algebra Course. Learn more about Stack Overflow the company, and our products. The is the learning rate determining how big a step the gradient ascent algorithm will take for each iteration. How can I access environment variables in Python? /Parent 13 0 R Is there a connector for 0.1in pitch linear hole patterns? multinomial, categorical, Gaussian, ). So, log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). % The best parameters are estimated using gradient ascent (e.g., maximizing log-likelihood) or descent (e.g., minimizing cross-entropy loss), where the chosen = g(). By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. $$. The Hartford Short Term Disability Payment Schedule, Kyle Damon Art, Articles G